Decompiler Design - Control Flow Graph |
|
|
Prev: Basic Blocks
Control Flow Graph
Now that we have a set of basic blocks to work with, it's much easier to implement a few more analyses and discover more about the structure of the program.
Because we've limited the construction of basic blocks to a single procedure, we'll be looking mostly at recovering statements at the procedure level. Analyzing the interaction between different procedures will be covered in the advanced section.
You may have noticed that in the basic block construction algorithm we saved the entry block into the procedure's data structure. Here's the relevant piece of code:
current_address = current_procedure->entry_address
block = get_block_at(current_address)
current_procedure->entry_block = block
workList.push = current_address
while workList not empty
current_address = workList.pop
block = get_block_at(current_address)
Why didn't we simply enter the while loop and just use the first
block in the blockList set?That's because the blockList set will be sorted by each block's start address, and while most procedures' entry points will be the lowest address of the procedure, it's possible that the entry point is actually generated by the compiler in the middle or at the end of the procedure (for example in presence of call-tail optimizations), so after the sorting, the first entry in blockList would not be our entry block anymore.
Note that while there's only one entry block per each procedure (we don't consider languages with multiple entry points, like Fortran), there can be multiple blocks that exit the procedure, since there can be many instruction sequences that end with a RET instruction.
Knowing that we always enter the procedure from a specific block gives us a place where to start inspecting the code. From the entry block, we can visit all other blocks by following the succs list. This is called forward analysis, because it follows the execution flow.
Some analysis requires to visit the blocks in the opposite
direction, that is from the exit point to the entry point.
But, how do we do that when there are multiple exit
blocks? The solution is to create a fake block, and make all
blocks that end with a return instruction the fake exit block's
predecessors (and automatically the fake exit block will become
their only successor).
With this trick, we can implement the algorithms
that require backward analysis, that is, that look at
the code in the direction opposite to the code's execution.
Here's an example of a control flow graph for a simple procedure without loops:
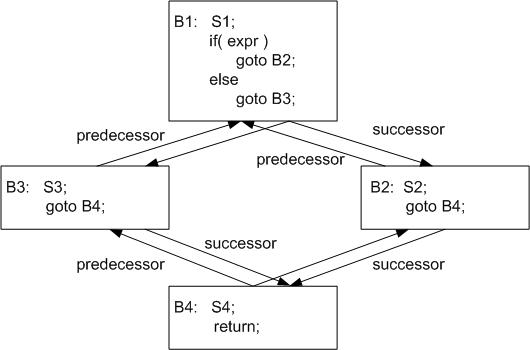
If the procedure has some loops, there will be a link between
the block at the bottom of the loop, and the block at the beginning
of the loop. When we visit the different blocks we have to make sure that
we don't endlessly analyze the blocks in the loop over and over again.
To do this, we add a visited field to each basic block, and we
check that field as we visit the blocks.
There are many possible orders in which to visit each block, and some algorithm depend on the visiting order. Here's an example of a forward visiting algorithm that will visit each block as soon as possible (that's why it's called "depth-first traversal" algorithm):
ForwardVisitBlocks(Block *block)
{
block->visited = true;
pre_visit:
// do some work
// visit all successors
for each succ block in block->succs
if(!succ->visited)
ForwardVisitBlocks(succ)
post_visit:
// do some work
}
// to start visiting the blocks...
for each block in blockList
block->visited = false
ForwardVisitBlocks(current_procedure->entry_block)
We can add code to execute an algorithm to one of two places: before we visit the successor blocks, or after we visit them. In C++ we would probably implement a "visitor" pattern and provide a pointer to an object implementing a specific analysis as an argument to the visitor.
You may have noticed from the picture above that we can recognize "if-then-else" sequences by checking whether the predecessors and the successors of two blocks are the same. There are several similar configurations of basic blocks that can be used to convert code full of gotos into structured code.
However, some such structures require special handling: loops.
Finding loops
A control flow graph allows us to find loops. The algorithm to identify which block belongs to a loop depends on knowing the dominator block for each loop, so first we have to compute the set of dominators per each block.
Next: Loop analysis